預期用途具情境依賴性
AI 安全與表現取決於程式、訓練數據、臨床環境及用戶互動。預期用途描述應涵蓋:地理及醫療機構類型;人群特徵;預期用戶;以及臨床情境與護理路徑。
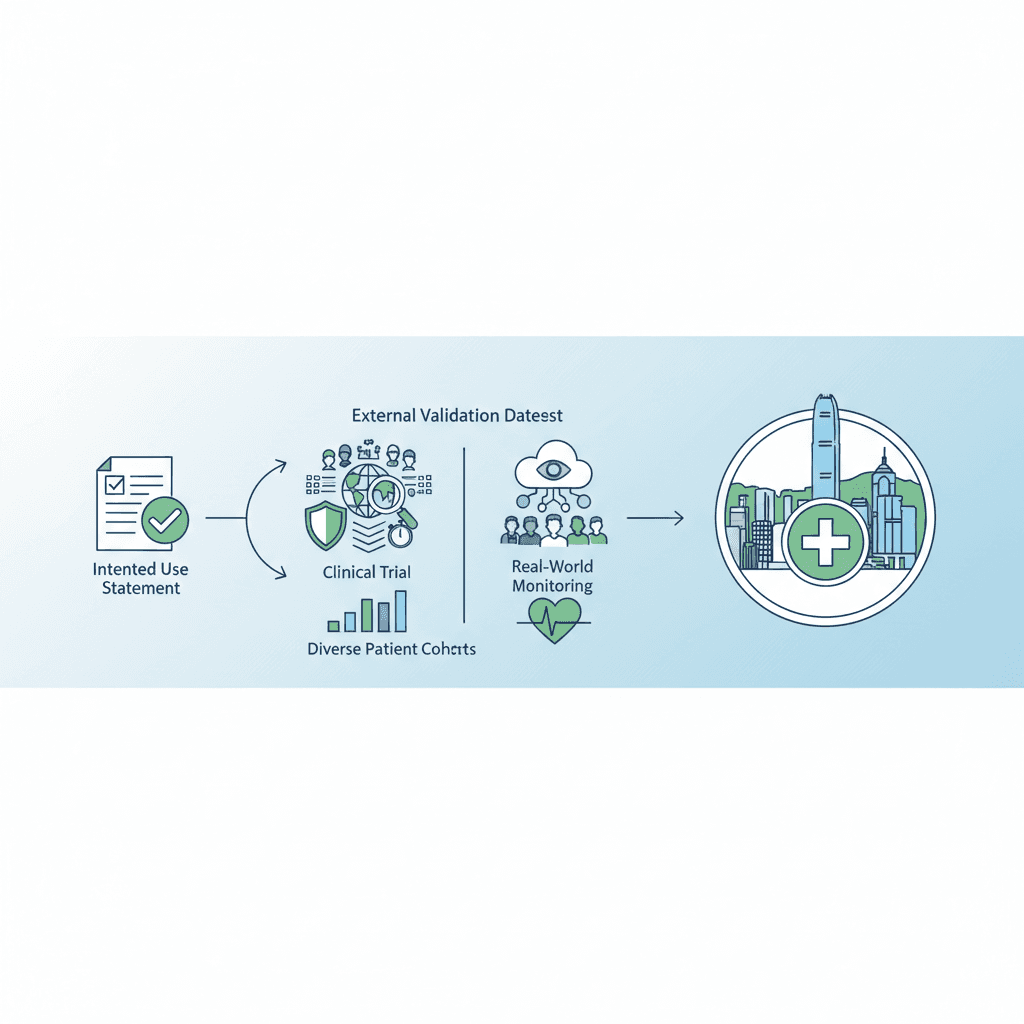
在某一流行病學環境訓練的工具可能在其他地方失效。開發者應說明已驗證表現的人群及環境,以及不適用的情況。
分析(技術)驗證
分析驗證使用數據而無需介入性臨床研究,以顯示模型在預期環境中穩健。WHO 期望透明記錄訓練、調校、測試及內部驗證數據集。
外部驗證須使用獨立、具部署人群代表性的數據集,並與訓練及測試數據分開。在香港應查詢驗證是否包括本地或相近族裔隊列;若無,在機構或監管要求下進行本地分析再驗證可能更穩妥。
按風險分級的臨床驗證
僅靠回顧性指標無法反映工作流程整合、用戶互動或路徑上的意外後果。WHO 支持分級證據:最高風險可採隨機對照試驗;其他情境可採前瞻性真實世界研究;部署後對高風險 AI 加強監測。
在隊列中報告性別、種族及族裔(在可行時)有助識別偏見及表現較差的人群。
基準測試及資源有限環境
WHO 指出基準測試或會增加,但重複使用同一基準數據更新模型可能引入偏見。監管能力有限的國家或依賴外部卷宗,但在情境不同時仍可进行本地分析驗證——對香港公私營並存及區內患者多樣性尤為相關。