Intended Use, Analytical & Clinical Validation
Define use cases clearly, validate externally on representative populations, and match clinical evidence to risk — from retrospective metrics to trials and post-deployment monitoring.
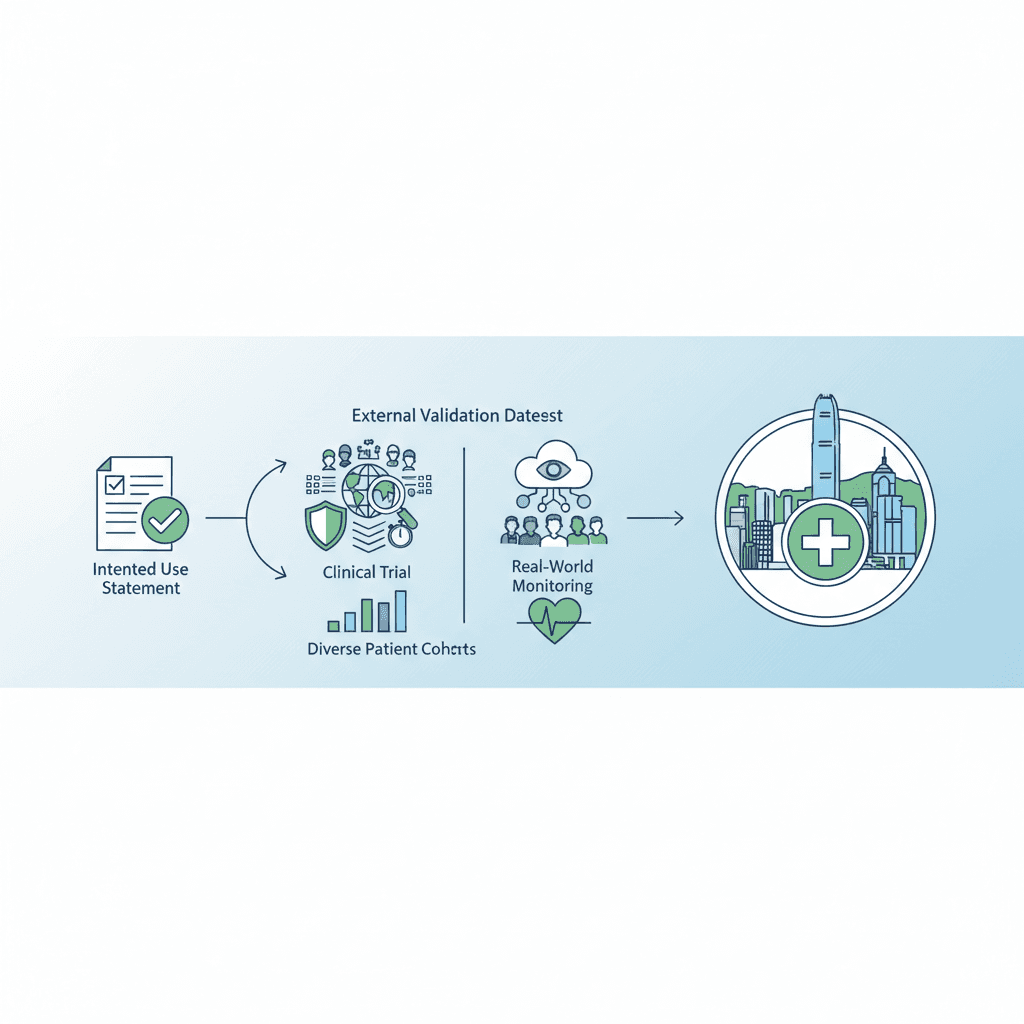
Intended use is context-dependent
AI safety and performance depend on code, training data, clinical setting, and user interaction. WHO stresses that intended use descriptions should cover:
- geography and type of care facility;
- population characteristics (age, sex, ethnicity, disease severity, comorbidities);
- intended user (clinician or patient); and
- the clinical situation and care pathway.
Tools trained on one epidemiology may fail elsewhere — for example, symptom checkers in regions with different disease patterns. Developers should state populations and settings for which performance is validated, and situations where use is not appropriate.
Analytical (technical) validation
Analytical validation uses data without interventional clinical studies to show the model is robust in the intended setting. WHO expects transparent documentation of training, tuning, testing, and internal validation datasets — including demographics and label quality.
External validation on an independent dataset representative of your deployment population is key. The external set should be separate from training and testing data. For Hong Kong, ask whether validation included local or ethnically similar cohorts; if not, local analytical re-validation may be prudent where regulators or institutions require it.
Clinical validation graded by risk
Retrospective metrics alone do not capture workflow integration, user interaction, or unintended pathway effects. WHO supports a graded evidence approach:
- Highest risk: randomized clinical trials may be appropriate when comparative clinical performance at the highest standard is required;
- Other contexts: prospective real-world implementation studies with relevant comparators;
- Post-deployment: more intense monitoring for high-risk AI through post-market surveillance.
Reporting gender, race, and ethnicity in cohorts — when feasible — helps identify bias and populations where the tool may underperform.
Benchmarking and limited-resource settings
WHO notes benchmarking may grow as more tools appear, but repeated use of the same benchmark data for successive model updates can introduce bias. Countries with limited regulatory capacity may rely on external dossiers yet still benefit from local analytical validation where context differs — a relevant consideration for Hong Kong's mixed public–private ecosystem and regional patient diversity.
Source: WHO — Regulatory considerations on artificial intelligence for health (2023)
Ready to test your knowledge?
Take a short quiz based on this article to check your understanding.
Take the quiz